
PyTorchでアヤメの分類を通してディープラーニングを学習しよう!!アヤメの分類の実行
Pythonでディープラーニングを学ために、まずはPyTorchでアヤメの分類を学習してみましょう。PyTorchでディープラーニングを行うために、まずはアヤメのデータをダウンロードしましょう。
PyTorchでアヤメの分類をしてディープラーニング!!
今回はアヤメのデータセットで行ったアヤメの分類の前準備を行ったことを前提としています。
実際にアヤメの分類を実行してみたいと思います。
目次
01. 訓練データとテストデータの用意
02. ニューラルネットワークの定義
03. 損失関数と最適化関数の定義
05. 学習
06. 結果の可視化
04. まとめ
01. 訓練データとテストデータの用意
## データのインプット
train_data, test_data, train_label, test_label = train_test_split(
data, label, test_size=0.2)
print("train_data size: {}".format(len(train_data)))
print("test_data size: {}".format(len(test_data)))
print("train_label size: {}".format(len(train_label)))
print("test_label size: {}".format(len(test_label)))�
## データのサイズを指定
train_data size: 120
test_data size: 30
train_label size: 120
test_label size: 30
まずは機械学習の目的を達成するためにデータを識別できるようにしましょう。
そこでデータを2つに分けます。
学習するための訓練データと予測したものを評価するためのテストデータに分けます。
train_test_splitでデータを分割することができます。
## テンソルにデータセット
train_x = torch.Tensor(train_data)
test_x = torch.Tensor(test_data)
train_y = torch.LongTensor(train_label)
test_y = torch.LongTensor(test_label)
## データをテンソルのデータにセットする
train_dataset = TensorDataset(train_x, train_y)
test_dataset = TensorDataset(test_x, test_y)
データ型をTensorに変換してTensorDatasetを使って特徴量とラベルを結合したデータセットを作成します。
## データセットの際の細かい設定をする
train_batch = DataLoader(
dataset = train_dataset,#データセットの指定
batch_size = 5,#バッチサイズの指定
shuffle = True,#シャッフルするかどうかの指定
num_workers = 2#コア数
)
test_batch = DataLoader(
dataset = test_dataset,
batch_size = 5,
shuffle = False,
num_workers = 2
)
## for文で回してサイズを確認する
for data, label in train_batch:
print("batch data size: {}".format(data.size()))
print("batch label size: {}".format(label.size()))
break
データセットが以上で終了しました。
データセットの準備は覚えておく必要があるのでしっかりと押さえておきましょう。
02. ニューラルネットワークの定義
## ニューラルネットワークを作成
class Net(nn.Module):
def __init__(self, D_in, H, D_out):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x)
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
## パラメータ表示
#ハイパーパラメータ
D_in = 4#入力次元
H = 100#隠れ層次元
D_out = 3#出力次元
epoch = 100#学習回数
## デバイスの指定
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
## ネットワーク実行
net = Net(D_in, H, D_out).to(device)
print("Device: {}".format(device))
以上がニューラルネットワークの定義とロードです。
基本的に型にハマった定義の仕方を覚えてしまえば問題ないと思います。
03. 損失関数と最適化関数の定義
#損失関数の定義
criterion = nn.CrossEntropyLoss()
#最適化関数の定義
optimizer = optim.Adam(net.parameters())
シンプルですが損失関数と最適化関数の準備はこれで完了です。
04. PythonとC言語の違いについて大まかな解説
## 学習に必要な空リストを作成
train_loss_list = []#学習損失
train_accuracy_list = []#学習データ正解率
test_loss_list = []#評価損失
test_accuracy_list = []#テストデータの正答率
#学習の実行
for I in range(epoch):
#学習の進行状況を表示
print('--------')
print("Epoch: {}/{}".format(I + 1, epoch))
#損失と正解率の初期化
train_loss = 0#学習損失
train_accuracy = 0#学習データの正答数
test_loss = 0#評価損失
test_accuracy = 0#テストデータの正答数
#学習モードに設定
net.train()
#ミニバッチごとにデータをロードして学習
for data, label in train_batch:
data = data.to(device)
label = label.to(device)
#勾配を初期化
optimizer.zero_grad()
#データを入力して予測値を計算
y_pred_prob = net(data)
#損失を計算
loss = criterion(y_pred_prob, label)
#勾配を計算
loss.backward()
#パラメータの更新
optimizer.step()
#ミニバッチごとの損失を蓄積
train_loss += loss.item()
#予測したラベルを予測確率から計算
y_pred_label = torch.max(y_pred_prob, 1)[1]
#ミニバッチごとに正解したラベル数をカウント
train_accuracy += torch.sum(y_pred_label == label).item() / len(label)
#ミニバッチの平均の損失と正解率を計算
batch_train_loss = train_loss / len(train_batch)
batch_train_accuracy = train__accuracy / len(train_batch)
#評価モードに設定
net.eval()
#評価時に自動微分をゼロにする
with torch.no_grad()
for data, label in test_batch:
data = data.to(device)
label = label.to(device)
#データを入力して予測値を計算
y_pred_prob = net(data)
#損失を計算
loss = criterion(y_pred_prob, label)
#ミニバッチごとの損失を備蓄
test_loss += loss.item()
#予測したラベルを予測確率から計算
y_pred_label = torch.max(y_pred_prob, 1)[1]
#ミニバッチごとに正解したラベル数をカウント
test_accuracy += torch.sum(y_pred_label == label).item() / len(label)
#ミニバッチの平均の損失と正解率を計算
batch_test_loss = test_loss / len(test_batch)
batch_test_accuracy = test_accuracy / len(test_batch)
#エポックごとに損失と正解率を表示
print("Train_Loss: {:.4f} Train_Accuracy: {:.4f}".format(batch_train_loss, batch_train_accurarcy))
print("Test_Loss: {:.4f} Test_Accuracy: {:.4f}".format(batch_test_loss, batch_test_accuracy))
#損失と正解率をリスト化して保存
train_loss_list.append(batch_train_loss)
train_accuracy_list.append(batch_train_accuracy)
test_loss_list.append(batch_test_loss)
test_accuracy_list.append(batch_test_accuracy)
## 実行結果
Epoch: 1/100
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Train_Loss: 1.1106 Train_Accuracy: 0.3333
Test_Loss: 0.9668 Test_Accuracy: 0.3333
--------
Epoch: 2/100
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Train_Loss: 0.8678 Train_Accuracy: 0.6500
Test_Loss: 0.7507 Test_Accuracy: 0.8000
--------
Epoch: 3/100
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Train_Loss: 0.7233 Train_Accuracy: 0.7000
Test_Loss: 0.6775 Test_Accuracy: 0.7333
--------
Epoch: 4/100
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Net(
(linear1): Linear(in_features=4, out_features=100, bias=True)
(linear2): Linear(in_features=100, out_features=3, bias=True)
)
Train_Loss: 0.6121 Train_Accuracy: 0.7500
Test_Loss: 0.5219 Test_Accuracy: 0.8000
...
学習段階はこれで終了です。
05. 結果の可視化
plt.figure()
plt.title('Train and Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(range(1, epoch+1), train_loss_list, color='blue',linestyle='-', label='Train_Loss')
plt.plot(range(1, epoch+1), test_loss_list, color='red', linestyle='--', label='Test_Loss')
plt.legend()
plt.figure()
plt.title('Train and Accuracy')
plt('Epoch')
plt('Accuracy')
plt.plot(range(1, epoch+1), train_accuracy_list, color='blue', linestyle='-', label='Test_Accuracy')
plt.plot(range(1, epoch+1), test_accuracy_list, color='red', linestyle='--', label='Test_Accuracy')
plt.legend()
plt.show()
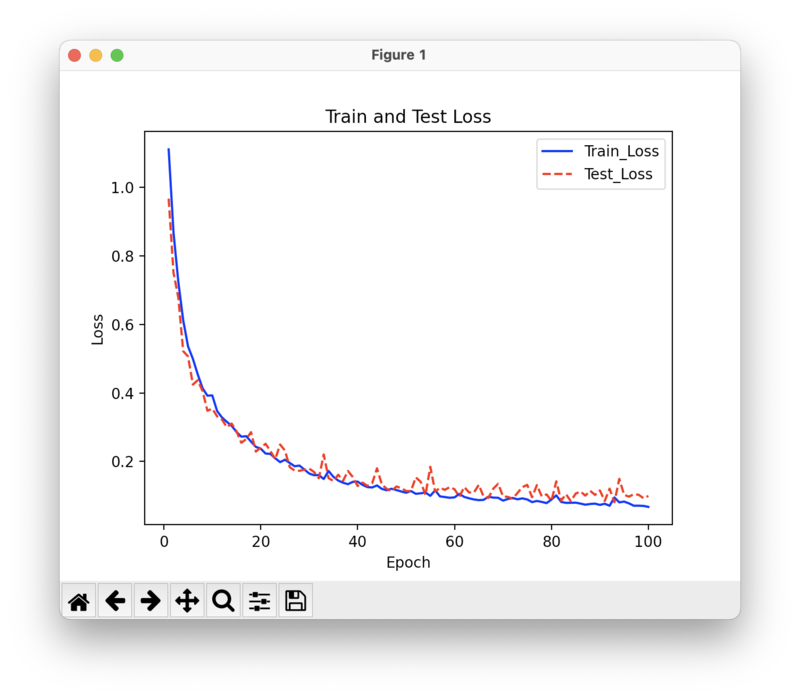
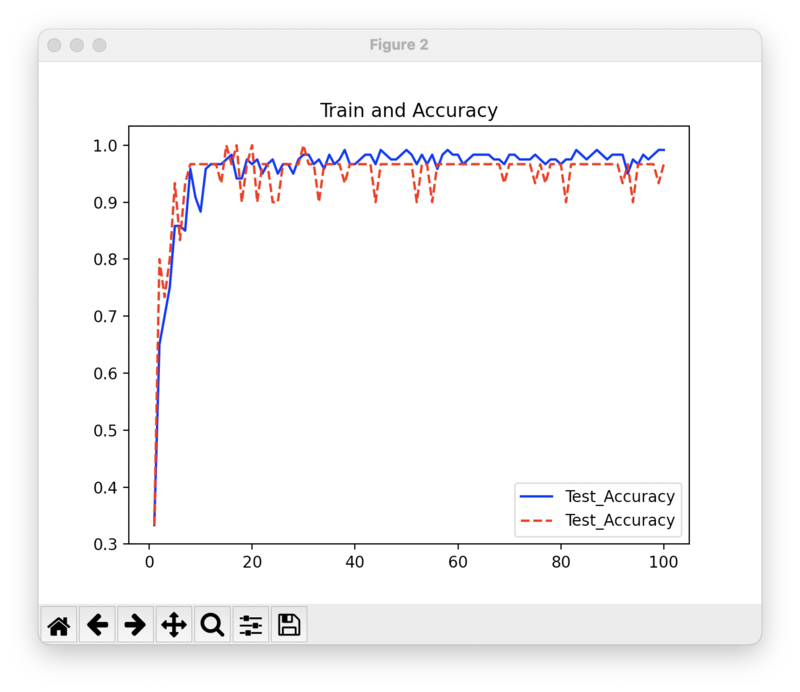
損失が小さくなり正解が増加していきます。
このようにグラフにすることで可視化することができます。
04. まとめ
PyTorchプログラミング入門を利用しながら実際に今回もやってみました。