
PyTorchでアヤメの分類を通してディープラーニングを学習しよう!!アヤメのデータ準備まで
PythonのPyTorchにを用いてディープラーニングを学びましょう。今回はアヤメの分類をするためにアヤメのデータを準備しました。PyTorchのデータフレームにアヤメのデータをセットするまでの内容です。
PyTorchでアヤメの分類をやってみよう
今回はアヤメの分類を行うためにデータセットとアヤメのデータ準備までを行います。
目次
01. ニューラルネットワークとは
02. アヤメの分類とは
03. アヤメの分類の流れ
04. アヤメのデータセット
05. データの前準備
06. まとめ
01. ニューラルネットワークとは
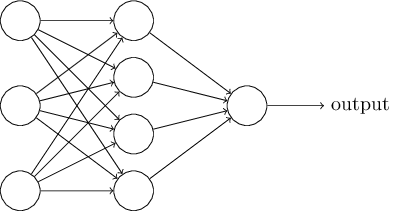
ニューラルネットワークのイメージ
ニューラルネットワークとは機械学習の1つです。
人間の脳神経回路をモデルにして人間のような学習の実現を目指します。
人の脳では、ニューロンと呼ばれる神経細胞が繋がりあって脳神経回路を構築します。
脳神経回路では、電気信号がどのように脳神経回路を流れるかによって情報が何であったか脳は認識しています。
機械学習におけるニューラルネットワークでも、同じようなイメージをして問題ありません。
ニューラルネットワークの最も単純なモデルを単純パーセプトロンと言います。
これは入力を受け取るいくつかの入力層と1つの出力層で構成されています。
ちょうど上にある画像の真ん中にある中間層を除いたものです。
出力層には、入力層で受け取った情報を重要度に応じてパラメータを調整したものが送られます。
パラメータとは重みであり、その重みはいわば情報の重要度であるとイメージしています。
送られてきた情報を基に、活性化関数を使用して出力する値を調節します。
ニューラルネットワークを多層にしたモデルを、ディープニューラルネットワークといいます。
このディープニューラルネットワークを利用して対象を自ら学習させる方法を、ディープラーニングといいます。
私たちは、ディープラーニングにおいてディープニューラルネットワークのパラメータを最適化するという作業をメインで行います。
02. アヤメの分類とは

アヤメの分類とは、花である何種類かのアヤメの特徴を学習させ、どの種類に属するか予測させるというものです。
実際に基本的なディープラーニングの例です。
アヤメの分類のやり方を学んで、ディープラーニングの基本的なやり方を押さえましょう。
03. アヤメの分類の流れ
・必要なライブラリーやパッケージをインポート
・データの前処理
・訓練データとテストデータの作成
・ニューラルネットワークの定義
・損失関数と最適化関数の定義
・学習
・結果
04. アヤメのデータセット
Pythonの機械学習ライブラリのscimitar-learnからアヤメのデータを取ってきます。
アヤメのデータセットの説明はDESCRiptionメソッドで確認することができます。
アヤメ属に属するセトサ、パージカラー、バージニカの3つの品種と4つの特徴量が収められていることが分かります。
150本分のアヤメのデータがあり、それぞれのアヤメに対して、がくの長さ、がくの幅、花びらの長さ、花びらの幅の4つの特徴量があります。
printを実行するとアヤメのデータが上記のようにして表示されます。
次にpandasというPythonのライブラリーを使用します。
データフレーム型に変換します。
第1引数にはアヤメの数値データを入れます。
第2引数の列名columnsにはアヤメの特徴量名のiris.feature_namesを渡します。
データセットの中身を確認するにはdf.head()とすることで上位5件のみを表示できます。
print(df.describe())で基本統計量を確認することができます。
データを可視化して見やすくしましょう。
seabornというライブラリーはデータの特徴などを可視化してデータを見やすくしてくれます。
ペアプロットsns.pairplotを使用して図示しました。

05. データの前準備
06. まとめ
お疲れ様でした。
ここまで読んでいただきありがとうございました。
今回はデータセットまでを行いました。
PyTorchプログラミング入門を利用しながら実際に今回もやってみました。
まずは基本を押さえます。
次回はアヤメの分類までを行います。
アヤメの分類まではインターネット上で公開されています。