
WgetでWebサイトをクローリングしてみる!WgetコマンドでWebサイトの情報を取得するまで!!
Wgetで任意のWebサイトをクローリングするための手順を解説をします。Wgetをコマンドで操作してWebサイトの情報をダウンロードします。Wgetならコマンド操作だけなので簡単です。
WebサイトをWgetを使ってクローリングしてみよう
今回は実際にWgetでクローリングしていきます。
クローリングについてやWgetコマンドを使うための事前準備については前回の記事、Wgetのコマンドでクローリングを見てください。
目次
01. Webサイトをクローリング
02. 実際にWgetでクローリングしてみる
03. treeコマンドでディレクトリ構造の確認
04. まとめ
01. Webサイトをクローリング
早速macOSでWgetを使ってみます。
homebrewをインストールし、Wgetもインストールされている状態であることを確認してください。
今回は、私たちのポートフォリオサイト(https://portfolio-of-us.herokuapp.com)をWgetコマンドを利用してクローリングしていきます。
ただ一つのページをクローリングするだけであれば以下のWgetコマンドで行うことができます。
しかし、リンクをたどってクローリングするのであればこのコードでは不十分です。
再帰的にダウンロードを行う-rオプションを使用します。
-rオプションは次々にファイルをダウンロードしてサーバーやネットワークに負荷がかかるので使用には注意が必要です。
Wgetでクローリングを行うにも、他のツールを利用するにも相手のサイトやサーバーに負荷をかけてはいけません。
これはルールなのでしっかりと理解して守りましょう。
-l(Lの小文字)オプションでリンクをたどる深さを制限したり、-wオプションでダウンロード間隔を空けたりしてなるべく負荷が少なくなるようにします。
実際のコードは以下のものです。
*下のコードでは自分たちで作成したサイトであることに加え、それほどリンクをたどる深さは深くないことがわかっていたので、-lオプションは省略しました。
--no-parentは、親ディレクトリをダウンロードしないというオプションです。
--restrict-file-names=nocontrolは、URLに日本語が含まれる場合にそのままのファイル名で保存するというオプションです。
ここで注意すべき点は、URLの末尾に/がついていなければならないということです。
末尾に/がついていないと、実行した際に「/portfolio-of-us.herokuapp.com/」以下のファイルがダウンロードされる際に「portfolio-of-us.herokuapp.com」という名前のディレクトリが作られて、「/portfolio-of-us.herokuapp.com」に対応するファイルが失われてしまうのです。
以上のことに注意しつつ先程のコードを実行すると、以下のようになります。

ファイルをダウンロードするたびにズラーっと文字が出てきますが正常に動いている証拠なので安心してください。
ダウンロードが終了すると、「ダウンロード完了」と表示されます。

これでWgetによるクローリングは完了です。
02. 実際にWgetでクローリングしてみる
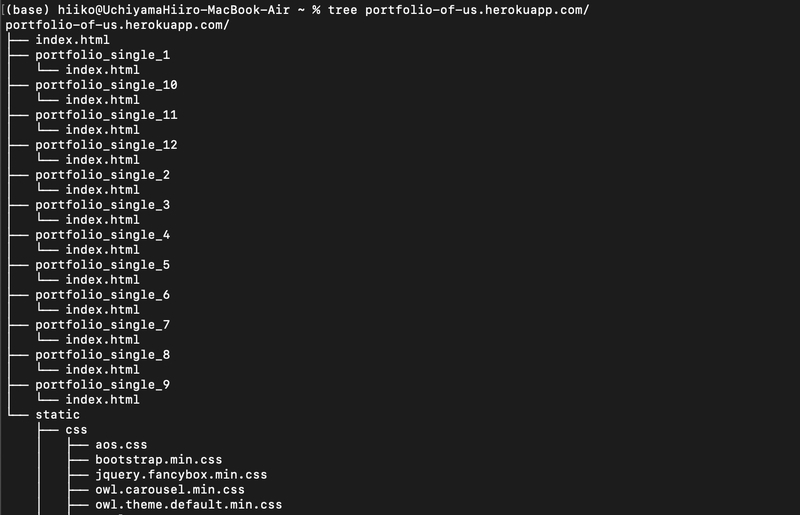
treeコマンドを使って、ダウンロードしたサイトのディレクトリ構造を見てみましょう。
treeコマンドは、macOSでは「brew install tree」、Ubuntuでは「sudo apt install -y tree」でインストールできます。
実行のコードは簡単です。以下のコードでできます。
実行結果は以下のようになります。(長すぎたので下部は省略しました)
04. まとめ
お疲れ様でした。
ここまで読んでいただきありがとうございました。
今回はWgetでWebサイトをクローリングをしてみることができたと思います。
クローリングのイメージを掴んでプログラムコードでもクローリングを実装できるようにしましょう。